Lesson 8.2: Protein Synthesis
Lesson 8.2: Protein Synthesis
Lesson Objectives
Discuss the meaning of DNA → RNA → Protein.
Describe how transcription makes RNA from a DNA template.
Explain the various types of modification mRNA undergoes before translation.
Discuss mRNA splicing and define introns and exons.
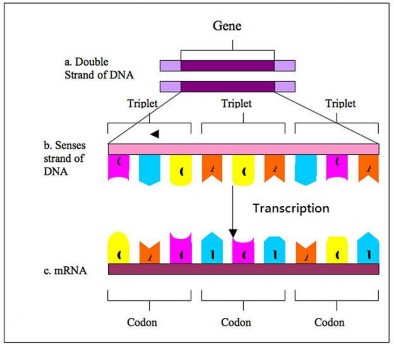
Explain how the Genetic Code is a three letter code, and describe its role in translating nucleotides into amino acids.
Explain that a reading frame is the group of three bases in which the mRNA is read, and describe how interrupting the reading frame may have severe consequences on the protein.
Discuss what is meant by the universal genetic code.
Describe translation. Explain that translation is the process of ordering the amino acids into a polypeptide; translation involves changing the language of nucleotides into the language of amino acids.
Illustrate the process of translation, describing how mRNA, rRNA, and tRNA all work together to complete the process.
Discuss what happens to the polypeptide after translation.
DNA → RNA → Protein
The central dogma of molecular biology describes the fundamental process that makes us all different. We all have different proteins. That is, though they may be the same types of proteins, such as we have the protein collagen found in bones, many of our proteins are slightly different and thus work slightly differently. If all our proteins acted the same way, we would all be exactly the same. But because we all have different DNA sequences, and DNA contains genes, and genes contain the information to encode an RNA molecule or a protein, we are all different.
So how does “DNA makes RNA makes protein” actually happen? The two processes nec- essary to make a protein from the information in DNA are transcription and translation. Transcription, which happens in the nucleus, uses the DNA sequence to make an RNA molecule. The RNA then leaves the nucleus and goes to the cytoplasm where translation occurs on a ribosome and produces a protein.
Transcription
//www.hhmi.org/biointeractive/media/DNAi_transcription_vo1-sm.mov.
Initiation
Transcription begins with the binding of RNA polymerase to the promoter of a gene. An eukaryotic promoter usually includes specific sequences that are recognized by transcription factors, which are proteins that aid in the binding of RNA polymerase to the correct place on the DNA. The transcription initiation complex formed by the promoter, transcription factors, and RNA polymerase signals the start, or initiation, of transcription. The DNA
unwinds and produces a small open complex, which allows RNA polymerase to “read” the DNA template and begin the synthesis of RNA.
Elongation
Transcription elongation involves the further addition of RNA nucleotides and the change of the open complex to a transcriptional complex. As the RNA transcript is assembled, DNA in front of RNA polymerase unwinds and transcription continues. As transcription progresses, RNA nucleotides are added to the 3’ end of the growing RNA transcript. The transcriptional complex has a short DNA-RNA hybrid, an 8 base-pair stretch in which the newly made RNA is temporarily hydrogen bonded to the DNA template strand. Unlike DNA replication, mRNA transcription can involve multiple RNA polymerases, allowing numerous mRNAs to be produced from a single copy of the gene. This step also involves a proofreading mechanism that can replace an incorrectly added RNA nucleotide.
Though both involve the detachment of the RNA from the DNA template, how this occurs is sur- prisingly distinct. Bacteria use two different strategies for transcription termination, Rho- dependent and Rho-independent termination. In Rho-dependent termination, a pro- tein factor called ”Rho” destabilizes the RNA-DNA hybrid, releasing the newly synthesized mRNA from the elongation complex. In Rho-independent termination, RNA transcription stops when the newly synthesized RNA molecule forms a hairpin loop followed by a run of uracils. This structure is the signal for the detachment of the RNA from the DNA. The DNA is now ready for translation.
The termination of transcription in eukaryotes is less well understood. The RNA poly- merase transcribes a polyadenylation signal. Polyadenylation is the addition of a string of A’s to the mRNA’s 3’ end and will be discussed in the next section. However, soon after the transcription of this signal, proteins cut the RNA transcript free from the polymerase and the polymerase eventually falls off the DNA. This process produces a pre-mRNA, an mRNA that is not quite ready to be translated.
Eukaryotic mRNA Processing
Newly transcribed eukaryotic mRNA is not ready for translation. This mRNA requires extensive processing, and so is known as pre-mRNA. The modification processes include splicing, the addition of a 5’ cap, editing, and polyadenylation. Once these process have occurred, the mature mRNA can be exported through the nuclear pore.
Humans have approximately 22,000 genes, yet make many more proteins. How? A process called alternative splicing allows one mRNA to produce many polypeptides. To under- stand this concept, the structure of the pre-mRNA must be discussed.
Eukaryotic pre-mRNA contains introns and exons. An exon is the region of a gene that contains the code for producing a protein. Most genes contain many exons, with each exon containing the information for a specific portion of a complete protein. In many species, a gene’s exons are separated by long regions of DNA that have no identified function. These long regions are introns, and must be removed prior to translation. Splicing is the process by which introns are removed (Figure 8.13). Sometimes a process called alternative splicing allows pre-mRNA messages to be spliced in several different configurations, allowing a single gene to encode multiple proteins. Splicing is usually performed by an RNA-protein complex called the spliceosome, but some RNA molecules have their own catalytic activity and are capable of acting like enzymes to catalyze their own splicing. For an animation of RNA splicing, see http://vcell.ndsu.edu/animations/mrnasplicing/first.htm.

5’ cap Addition
How does the mRNA know it is time to leave the nucleus? Once the mRNA leaves the nucleus, how does it find a ribosome? A signal on the front, 5’-end of the mRNA helps with both jobs. This signal is the 5’ cap. The 5’ cap is a modified guanine nucleotide added to the 5’-end of the pre-mRNA. This 5’ cap is crucial for recognition and proper attachment of the mRNA to the ribosome, as well as protection from exonucleases, enzymes that degrade nucleic acids.
Editing
In certain instances, the nucleotide sequence of an mRNA will be changed to allow the mRNA to produce multiple proteins. This process is called editing. The classic example is editing of the apolipoprotein B (APOB) mRNA in humans. The APOB protein occurs in the plasma in two main forms, APOB48 and APOB100. The first is synthesized exclusively by the small intestine, the second by the liver. Both proteins are coded for by the same gene, which is transcribed into a single pre-mRNA. Editing creates a premature (early) stop codon, which upon translation produces a smaller protein. As a result of the RNA editing, APOB48 and APOB100 share a common N-terminal sequence, but APOB48 lacks APOB100’s C-terminal region.
Polyadenylation
In eukaryotic cells, the transcription of the polyadenylation signals indicates the termination of the process. The mRNA transcript is then cut off of the RNA polymerase and freed from the DNA. The cleavage site is characterized by the presence of the sequence AAUAAA near the end of the transcribed message. Polyadenylation then occurs. Polyadenylation is the addition of a poly(A) tail to the 3’-end of the mRNA. The poly(A) tail may consist of as many as 80 to 250 adenosine residues. The poly(A) tail protects the mRNA from degradation by exonucleases. Poladenylation is also important for transcription termination, export of the mRNA from the nucleus, and translation. For an animation on RNA polyadenylation, see http://vcell.ndsu.edu/animations/mrnaprocessing/first.htm.
The Genetic Code
So how exactly is the language of nucleotides used to code for the language of amino acids? How can a code of only As, Cs, Gs, and Us carry information for 20 different amino acids? The genetic code is the code in which the language of nucleotides is used to create the language of amino acids.
Cracking the Code
A code of at least three letters has to be the answer. A one letter code would only be able to code for four amino acids. A two letter code could only code for 16 amino acids. With a three letter code, there are 64 possibilities. As there are 20 amino acids, the answer must be a code of at least three letters.
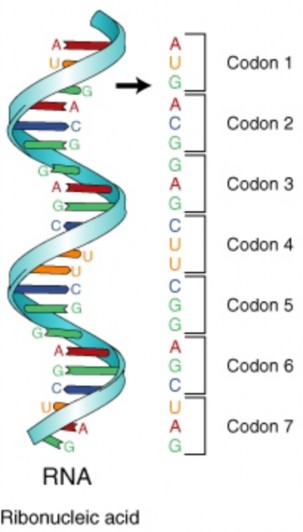
In 1961, Francis Crick and Sydney Brenner demonstrated the presence of codons, that is, three bases of RNA that code for one amino acid (Figure 8.14). Also in 1961, Marshall Nirenberg and Heinrich Matthaei at the National Institutes of Health (NIH) demonstrated that a poly(U) RNA sequence was translated into a polypeptide consisting of only the amino acid phenylalanine. This proved that the codon UUU coded for the amino acid phenylalanine. Extending this work, Nirenberg and his coworkers were able to determine the nucleotide makeup of 54 of the 64 codons. Others determined the remainder of the genetic code (Figure8.15).
Start and Stop Codons
The codon AUG codes for the amino acid methionine. This codon is also the start codon which begins every translation of every amino acid chain. The translational machinery “reads” the mRNA codon by codon until it reaches a stop, or termination, codon. Stop
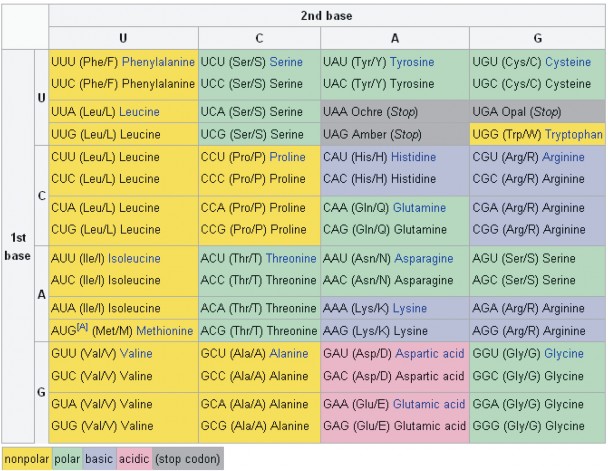
codons are not associated with a tRNA or amino acid. Three are three stop codons: UAG, UGA, UAA.
The Reading Frame
The reading frame is the frame of three bases in which the mRNA is read or translated. Every sequence can be read in three reading frames, each of which will produce a different amino acid sequence. For example, in the sequence GCAUGGGGGUCUAG, the reading frame can begin with either the first G, the first C, or the first A. As stated above, trans- lation starts with the start codon which consists of the three bases AUG. Each subsequent codon is translated until an in-frame stop codon is reached. In the example above, the polypeptide sequence would be: methionine – glycine – valine – stop.
Mutations that disrupt the reading frame by insertions or deletions of a non-multiple of 3 nucleotide bases are known as frameshift mutations. Take the example:
THE BIG FAT CAT ATE THE RED RAT
A deletion mutation that disrupts the reading frame, results in a message that does not make any sense. If the ‘B’ is deleted:
THE IGF ATC ATA TET HER EDR AT
Once the reading frame is disrupted, the mRNA may not be translated properly. These mutations may impair the function of the resulting protein, if the protein is even formed. Many frameshift mutations result in a premature stop codon, in other words, a stop codon that come earlier than normal during translation. This would result in a smaller protein, most likely without normal function.
Degeneracy of the Universal Genetic Code
When there are 64 codon combinations for 20 amino acids (and stop codons), there is going to be some overlap. Within the genetic code there is redundancy but no ambiguity. For example, the codons GGG, GGA, GGC, and GGU all encode the amino acid glycine, but none encode another amino acid. Degenerate codons often differ in the third position.
The genetic code is said to be universal. That is, the same code is utilized by the simplest prokaryotic organism and by humans. This universality is a tremendous benefit to mankind. If a human gene is placed in a bacteria, it looks just like a piece of DNA to the bacteria. The human As, Cs, Gs, and Ts look just like the bacteria’s As, Cs, Gs, and Ts. So, the bacterial proteins will transcribe and translate this DNA, making a human protein.
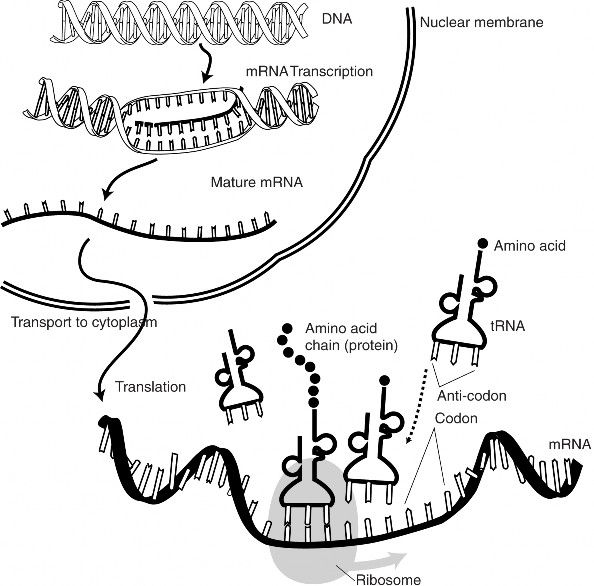
But how exactly are these proteins made? We have been referring to mRNA’s, tRNA’s, ribosomes, codons and the genetic code throughout this chapter. How do they all come together to make a protein? The process is called translation.
Translation is “RNA → protein.” In other words, translation is the transfer of the instructions in RNA to a protein made of amino acids. Translation uses the products of transcription, mRNA, tRNA, and rRNA, and converts the mRNA sequence into a polypeptide according to the genetic code. The mRNA moves to the cytoplasm and interacts with a ribosome, which serves as the site of translation. Translation proceeds in three phases: initiation, elongation and termination.
To understand translation, first we need to understand the ribosome. Ribosomes are com- posed of two subunits, a small subunit and a larger subunit. Prokaryotic subunits are named the 30S and 50S subunits; eukaryotic subunits are named the 40S and 60S subunits. Dur- ing translation the tRNA molecules are literally “inside” the ribosomal subunits, as they sit on the mRNA strand. When tRNAs come to the ribosome, adjacent amino acids are brought together, allowing the ribosome to catalyze the formation of the peptide bond be- tween amino acids. The ribosome has three tRNA binding sites: the A site, the P site, and the E site (Figure 8.16). The A site binds a tRNA with an attached amino acid. The P site contains the tRNA with the growing polypeptide chain attached, and the E site contains the tRNA that no longer has an attached amino acid. This tRNA is preparing to exit the ribosome. A single mRNA can be translated simultaneously by multiple ribosomes. For an animation of translation, see http://www.hhmi.org/biointeractive/media/DNAi_ translation_vo1-sm.mov.
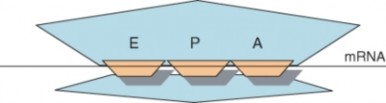
Figure 8.16: This cartoon depicts the relative location of the E, P, and A sites within the ribosome. The A site binds a tRNA bound to an amino acid, the P site binds a tRNA bound to the polypeptide being synthesized, and the E site binds a tRNA without an attached amino acid before the tRNA exits the ribosome. (1)
Initiation in Prokaryotes
The initiation of translation in prokaryotes involves the assembly of the ribosome and addi- tion of the first amino acid, methionine. The 30S ribosomal subunit attaches to the mRNA. Next, the specific methionine tRNA is brought into the P. The anticodon of this tRNA will bind to the AUG codon on the mRNA. This is the only time a tRNA will be brought into the P site; all successive tRNA’s will be brought to the A site as translation continues. The 50S ribosomal subunit then binds to the 30S subunit, completing the ribosome.
Elongation
Elongation is fairly similar between prokaryotes and eukaryotes. As translation begins, the start tRNA is sitting on the AUG codon in the P site of the ribosome, so the next codon available to accept a tRNA is at the A site. Elongation proceeds after initiation with the binding of an tRNA to the A site. The next tRNA binds to the codon, bringing the appropriate amino acid to the ribosome, and a peptide bond joins between the start methionine and the next amino acid. The entire ribosome complex moves along the mRNA, sending the first tRNA into the E site and the tRNA with the growing polypeptide into the P site. The A site is now empty and ready to accept another tRNA. The first tRNA now leaves the ribosome. The A site accepts a tRNA with an attached amino acid, a peptide bond forms between the two adjacent amino acids, and the process continues.
Termination
Termination of translation occurs when the ribosome comes to one of the three stop codons, for which there is no tRNA. At this point, a protein called a release factor binds to the A site. The release factor causes the addition of a water molecule to the polypeptide chain, resulting in the release of the completed chain from the tRNA and ribosome. The ribosome, release factor, and tRNAs then dissociate and translation is complete. The process of translation is summarized in Figure 8.17.
Post-Translational Modification and Protein Folding
The events following protein synthesis often include post-translational modification of the peptide chain and folding of the protein into its functional conformation. During and after synthesis, polypeptide chains often fold into secondary and then tertiary structures. These levels of organization were discussed in the chapter titled Chemical Basis of Life. Briefly, the primary structure of the protein is determined by the gene. The secondary and ter- tiary structures are determined by interactions between the amino acids within the protein (Figure 8.18).
Many proteins undergo post-translational modification, allowing them to then perform their specific function. This may include the formation of disulfide bridges or attachment of any of a number of biochemical functional groups, such as phosphate groups, carbohydrates or lipids. Certain amino acids may be removed, or the polypeptide chain may be cut into two pieces. Lastly, two or more polypeptides may interact with each other, forming a functional protein with a quaternary structure.
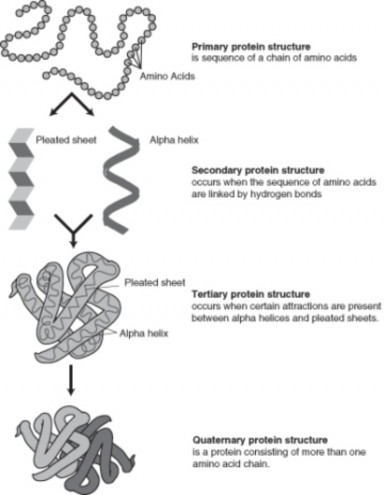
Figure 8.18: The four stages of protein folding. (19)
Lesson Summary
“DNA makes RNA makes protein” is the central dogma of molecular biology.
Transcription is the transfer of the genetic instructions from DNA to RNA.
Translation is the process of using the information in the mRNA to order amino acids into a polypeptide.
Transcription begins with the binding of RNA polymerase to the promoter of a gene.
Newly transcribed eukaryotic mRNA is not ready for translation; this mRNA requires extensive processing, including splicing and polyadenylation.
A codon is a three base code for one amino acid.
Start and stop codons signal the beginning and end of translation.
There are three stop codons.
The reading frame is the frame of three bases in which the mRNA is read.
The genetic code is universal.
Translation involves the interactions of the three types of RNA.
After the protein is made, it must fold into its functional conformation.
Review Questions
Further Reading / Supplemental Links
What is meant by “DNA → RNA → Protein?”
Describe transcription.
List some of the modification mRNAs undergoes before translation.
Define introns and exons.
Describe mRNA splicing.
Describe the role of the Genetic Code in translation.
What is a reading frame?
Discuss what is meant by the universal genetic code.
Explain translation.
What is protein folding?
Transcription Animation
http://www-class.unl.edu/biochem/gp2/m_biology/animation/gene/gene_a2.html
Campbell, N.A. and Reece, J.B. Biology, Seventh Edition, Benjamin Cummings, San Francisco, CA, 2005.
Biggs, A., Hagins, W.C., Kapicka, C., Lundgren, L., Rillero, P., Tallman, K.G., and Zike, D., Biology: The Dynamics of Life, California Edition, Glencoe Science, Colum- bus, OH, 2005.
Nowicki S., Biology, McDougal Littell, Evanston, IL, 2008.
The National Health Museum:
http://www.accessexcellence.org/RC/VL/GG/rna_synth.html
Genetic Science Learning Center: http://learn.genetics.utah.edu/units/basics/transcribe/
Kimball’s Biology Pages:
http://users.rcn.com/jkimball.ma.ultranet/BiologyPages/C/Codons.html
The National Health Museum:
http://www.accessexcellence.org/RC/VL/GG/genetic.html
The National Health Museum:
http://www.accessexcellence.org/RC/VL/GG/protein_synthesis.html
Vocabulary
5’ cap A modified guanine nucleotide added to the 5’-end of the pre-mRNA; crucial for recognition and proper attachment of the mRNA to the ribosome.
A site Within the ribosome; binds a tRNA with an attached amino acid.
alternative splicing Process by which pre-mRNA messages can be spliced in several dif- ferent configurations, allowing a single gene to encode multiple proteins.
E site Within the ribosome; contains the tRNA that no longer has an attached amino acid.
editing The process of changing the nucleotide sequence of an mRNA to allow the mRNA to produce multiple proteins.
elongation The segment of transcription that the further addition of RNA nucleotides; also refers to the process during translation of adding additional amino acids to the growing polypeptide chain.
exon The region of a gene that contains the code for producing a protein.
frameshift mutation Mutation that disrupt the reading frame by insertions or deletions of a non-multiple of three nucleotide bases.
gene A segment of DNA that contains the information necessary to encode an RNA molecule or a protein.
genetic code The code in which the language of nucleotides is used to create the language of amino acids.
initiation The start of transcription; signaled by the transcription initiation complex formed by the promoter, transcription factors, and RNA polymerase; also refers to the start of translation.
intron Long region of DNA that has no identified function; separates exons.
P site Within the ribosome; contains the tRNA with the growing polypeptide chain at- tached.
pre-mRNA Newly transcribed eukaryotic mRNA; not yet ready for translation.
polyadenylation The addition of a string of adenines to the mRNAs 3’-end; signals the termination of translation in eukaryotes.
reading frame The frame of three bases (codon) in which the mRNA is translated.
Rho-dependent termination Involves a protein factor (Rho), which destabilizes the RNA-DNA hybrid, releasing the newly synthesized mRNA from the elongation com- plex.
ribosome Non-membrane bound organelle; site of protein synthesis.
RNA polymerase The enzyme that reads a template strand of DNA during transcription to synthesize the complementary RNA strand.
splicing The process by which introns are removed from pre-mRNA.
spliceosome RNA-protein complex that usually performs splicing of the pre-mRNA.
termination The end of transcription; involves the detachment of the RNA from the DNA template; also refers to the end of translation when the ribosome comes to one of the three stop codons, for which there is no tRNA.
transcription The process that uses the DNA sequence to make an mRNA molecule.
translation The process of converting the language of nucleotides (in the mRNA) into the language of amino acids.
We know what happens when everything goes right. The result is a correctly made protein that functions properly and maintains homeostasis.
However, what happens when things do not go right? What can lead to a protein not being made correctly or not functioning correctly?
Can you think of possible mechanisms that may that can interfere with protein syn- thesis?
How can a change in the DNA sequence lead to a different protein?
- Log in or register to post comments
- Email this page