Lesson 8.1: DNA and RNA
Lesson 8.1: DNA and RNA
Lesson Objectives
Discuss how the work of Griffith, Avery, Hershey, and Chase demonstrated that DNA is the genetic material.
Define transformation and explain that transformation is the change in genotype and phenotype due to the assimilation of the external DNA by a cell.
Discuss the findings of Chargaff. Describe the importance of the finding that in DNA, the amount of adenine and thymine were about the same and that the amount of guanine and cytosine were about the same. This finding lead to the base pairing rules.
Explain Watson and Crick’s double helix model of DNA.
Describe how DNA is replicated.
Explain the importance of the fact that during DNA replication, each strand serves as a template to make a complementary DNA strand.
Describe the structure and function of RNA.
Discuss the role of the three types of RNA: mRNA, rRNA, and tRNA.
Introduction
What tells the first cell of an organism what to do? How does that first cell know to become two cells, then four cells, and so on? Does this cell have instructions? What are those instructions and what do they really do? What happens when those instructions don’t work properly? Are the “instructions” the genetic material? Though today it seems completely obvious that Deoxyribonucleic acid, or DNA, is the genetic material, this was not always known.
Practically everything a cell does, be it a liver cell, a skin cell, or a bone cell, it does because of proteins. It is your proteins that make a bone cell act like a bone cell, a liver cell act like a liver cell, or a skin cell act like a skin cell. In other words, it is the proteins that give an organism its traits. We know that it is your proteins that that make you tall or short, have light or dark skin, or have brown or blue eyes. But what tells those proteins how to act? It is the structure of the protein that determines what it does. And it is the order and type of amino acids that determine the structure of the protein. And that order and type of amino acids that make up the protein are determined by your DNA sequence.
The relatively large chromosomes that never leave the nucleus are made of DNA. And, as proteins are made on the ribosomes in the cytoplasm, how does the information encoded in the DNA get to the site of protein synthesis? That’s where RNA comes into this three-player act.
That’s known as the central dogma of molecular biology. It states that “DNA makes RNA makes protein.” This process starts with DNA. And first DNA had to be identified as the genetic material.
The Hereditary Material
For almost 100 years, scientists have known plenty about proteins. They have known that proteins of all different shapes, sizes, and functions exist. For this reason, many scientists believed that proteins were the heredity material. It wasn’t until 1928, when Frederick Griffith identified the process of transformation, that individuals started to question this concept. Griffith demonstrated that transformation occurs, but what was the material that caused the transforming process?
Griffith, Avery, Hershey and Chase
Griffith was studying Streptococcus pneumoniae, a bacterium that infects mammals. He used two strains, a virulent S (smooth) strain and a harmless R (rough) strain to demonstrate the transfer of genetic material. The S strain is surrounded by a polysaccharide capsule, which protects it from the host’s immune system, resulting in the death of the host, while the R strain, which does not have the protective capsule, is defeated by the host’s immune system. Hence, when mammalian cells are infected with the R strain bacteria, the host does not die (Figure 8.1).
Griffith infected mice with heat-killed S strain bacteria. As expected, the heat-killed bacteria, as they were dead, had no effect on the mice (Figure 1). But then he tried something different.
He mixed the remains of heat-killed S strain bacteria with live R strain bacteria and injected the mixture into mice. Remember, separately both of these bacteria are harmless to the mice. And yet the mice died (Figure 8.1). Why? These mice had both live R and live S strain bacteria in their blood. How? Griffith concluded that the R strain had changed, or transformed, into the lethal S strain. Something, such as the ”instructions” from the remains of the S strain, had to move into the R strain in order to turn the harmless R strain into the lethal S strain. This material that was transferred between strains had to be the heredity material. But the transforming material had yet to be identified. Transformation is now known as the change in genotype and phenotype due to the assimilation of external DNA (heredity material) by a cell.
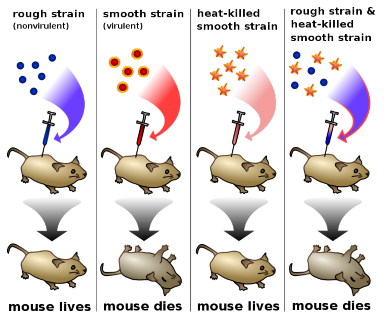
Over the next decade, scientists, led by Oswald Avery, tried to identify the material involved in transformation. Avery, together with his colleagues Maclyn McCarty and Colin MacLeod, removed various organic compounds from bacteria and tested the remaining compounds for the ability to cause transformation. If the remaining material did not cause transformation, than that material could not be the heredity material. Avery treated S strain bacteria with protease enzymes, which remove proteins from cells, and then mixed the remainder with R strain bacteria. The R strain bacteria transformed, meaning that proteins did not carry the genes for causing the disease. Then the remnants of the S strain bacteria were treated with deoxyribonuclease, an enzyme which degrades DNA. After this treatment, the R strain bacteria no longer transformed. This indicated that DNA was the heredity material. The year was 1944.
However, this finding was not widely accepted, partly because so little was known about DNA. It was still thought that proteins were better candidates to be the heredity material. The structure of DNA was still unknown, and many scientists were not convinced that genes from bacteria and more complex organisms could be similar.
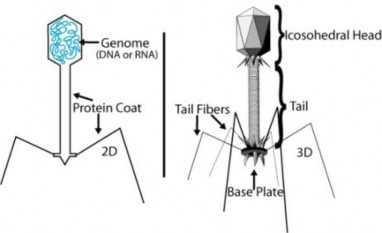
In 1952, Alfred Hershey and Martha Chase put this skepticism to rest. They conclusively demonstrated that DNA is the genetic material. Hershey and Chase used the T2 bacte- riophage, a virus that infects bacteria, to prove this point. A virus is essentially DNA (or RNA) surrounded by a protein coat (Figure 8.2). To reproduce, a virus must infect a cell and use that host cell’s machinery to make more viruses. The T2 bacteriophage can quickly turn an Escherichia coli (E. coli) bacteria into a T2 producing system. But to do that, the genetic material from T2, which could only be protein or DNA, must be transferred to the bacteria. Which one was it?
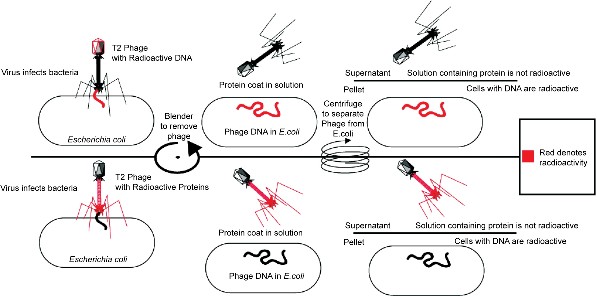
Hershey and Chase performed a series of classic experiments, taking advantage of the fact that T2 is essentially just DNA and protein. In the experiments, T2 phages with either radioactive 32P-labeled DNA or radioactive 35S-labeled protein were used to infect bacteria. Either the radioactive proteins or radioactive DNA would be transferred to the bacteria. Identifying which one is transferred would identify the genetic material. In both experiments, bacteria were separated from the phage coats by blending, followed by centrifugation. Only the radioactively labeled DNA was found inside the bacteria, whereas the radioactive proteins stayed in the solution (Figure 8.3). These experiments demonstrated that DNA is the genetic material and that protein does not transmit genetic information.
It was known that DNA is composed of nucleotides, each of which contains a nitrogen- containing base, a five-carbon sugar (deoxyribose), and a phosphate group. In these nu- cleotides, there is one of the four possible bases: adenine (A), guanine (G), cytosine (C), or thymine (T) (Figure 8.4).
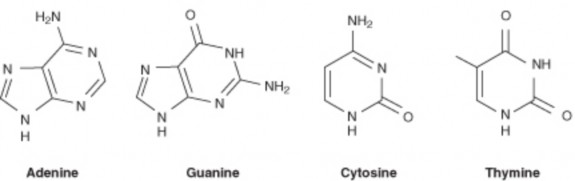
Figure 8.4: Chemical structure of the four nitrogenous bases in DNA. (13)
Erwin Chargaff proposed two main rules that have been appropriately named Chargaff’s rules. In 1947 he showed that the composition of DNA varied from one species to another. This molecular diversity added evidence that DNA could be the genetic material. Chargaff also determined that in DNA, the amount of one base always approximately equals the amount of a particular second base. For example, the number of guanines equals the number of cytosines, and the number of adenines equals the number of thymines. Human DNA is 30.9% A and 29.4% T, 19.9% G and 19.8% C. This finding, together with that of the DNA structure, led to the base-pairing rules of DNA.
The Double Helix
In the early 1950s, Rosalind Franklin started working on understanding the structure of DNA fibers. Franklin, together with Maurice Wilkins, used her expertise in x-ray diffraction photographic techniques to analyze the structure of DNA. In February 1953, Francis Crick and James D. Watson of the Cavendish Laboratory in Cambridge University had started to build a model of DNA. Watson and Crick indirectly obtained Franklin’s DNA X-ray diffraction data demonstrating crucial information into the DNA structure. Francis Crick and James Watson (Figure 8.5) then published their double helical model of DNA in Nature on April 25th, 1953.

Figure 8.5: James Watson (left) and Francis Crick (right). (14)
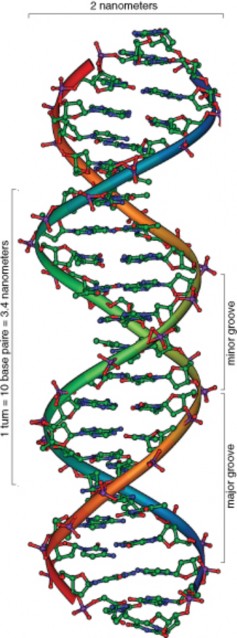
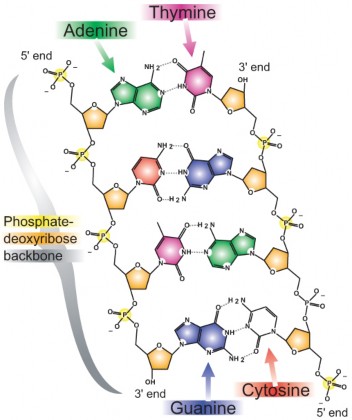
DNA has the shape of a double helix, just like a spiral staircase (Figure 8.6). There are two sides, called the sugar-phosphate backbone, because they are made from alternating phosphate groups and deoxyribose sugars. The “steps” of the double helix are made from the base pairs formed between the nitrogenous bases. The DNA double helix is held together by hydrogen bonds between the bases attached to the two strands.
The double helical nature of DNA, together with the findings of Chargaff, demonstrated the base-pairing nature of the bases. Adenine always pairs with thymine, and guanine always pairs with cytosine (Figure 8.7). Because of this complementary nature of DNA, the bases on one strand determine the bases on the other strand. These complementary base pairs explain why the amounts of guanine and cytosine are present in equal amounts, as are the amounts of adenine and thymine. Adenine and guanine are known as purines. These bases consist of two ring structures. Purines make up one of the two groups of nitrogenous bases. Thymine and cytosine are pyrimidines, which have just one ring structure. By having a purine always combine with a pyrimidine in the DNA double helix, the distance between the two sugar-phosphate backbones is constant, maintaining the uniform shape of the DNA molecule.
The two strands in the DNA backbone run in anti-parallel directions to each other. That is, one of the DNA strands is built in the 5’ → 3’ direction, while the complementary strand is built in the 3’ → 5’ direction. In the DNA backbone, the sugars are joined together by phosphate groups that form bonds between the third and fifth carbon atoms of adjacent sugars. In a double helix, the direction of the nucleotides in one strand is opposite to their direction in the other strand. 5’ and 3’ each mark one end of a strand. A strand running in the 5’→ 3’ direction that has adenine will pair with base thymine on the complementary
strand running in 3’→ 5’ direction.
So it is this four letter code, made of just A, C, G, and T, that determines what the organism will become and what it will look like. How can these four bases carry so much information? This information results from the order of these four bases in the chromosomes. This sequence carries the unique genetic information for each species and each individual. Humans have about 3,000,000,000 bits of this information in each cell. A gorilla may also have close to that amount of information, but a slightly different sequence. For example, the sequence AGGTTTACCA will have different information than CAAGGGATTA. The closer the evolutionary relationship is between two species, the more similar their DNA sequences will be. For example, the DNA sequences between two species of reptiles will be more similar than between a reptile and an elm tree.
DNA sequences can be used for scientific, medical, and forensic purposes. DNA sequences can be used to establish evolutionary relationships between species, to determine a person’s susceptibility to inherit or develop a certain disease, or to identify crime suspects or victims. Of course, DNA analysis can be used for other purposes as well. So why is DNA so useful for these purposes? It is useful because every cell in an organism has the same DNA sequence. For this to occur, each cell must have a mechanism to copy its entire DNA. How can so much information be exactly copied in such a small amount of time?
DNA Replication
DNA replication is the process in which a cell’s entire DNA is copied, or replicated. This process occurs during the Synthesis (S) phase of the eukaryotic cell cycle. As each DNA strand has the same genetic information, both strands of the double helix can serve as templates for the reproduction of a new strand. The two resulting double helices are identical to the initial double helix. For an animation of DNA replication, see http://www. hhmi.org/biointeractive/media/DNAi_replication_vo1-sm.mov.
Helicase and Polymerase
DNA replication begins as an enzyme, DNA helicase, breaks the hydrogen bonds holding the two strands together and forms a replication fork. The resulting structure has two branching strands of DNA backbone with exposed bases. These exposed bases allow the DNA to be “read” by another enzyme, DNA polymerase, which then builds the complementary DNA strand. As DNA helicase continues to open the double helix, the replication fork grows.
The two new strands of DNA are “built” in opposite directions, through either a leading strand or a lagging strand. The leading strand is the DNA strand that DNA polymerase constructs in the 5’ → 3’ direction. This strand of DNA is made in a continuous manner,
moving as the replication fork grows. The lagging strand is the DNA strand at the opposite side of the replication fork from the leading strand. It goes in the opposite direction, from 3’ to 5’. DNA polymerase cannot build a strand in the 3’ → 5’ direction. Thus, this “lagging” strand is synthesized in short segments known as Okazaki fragments. On the lagging strand, an enzyme known as primase builds a short RNA primer. DNA polymerase is then able to use the free 3’ OH group on the RNA primer to make DNA in the 5’ → 3’ direction. The RNA fragments are then degraded and new DNA nucleotides are added to fill the gaps where the RNA was present. Another enzyme, DNA ligase, is then able to attach (ligate) the DNA nucleotides together, completing the synthesis of the lagging strand (Figure 8.8).
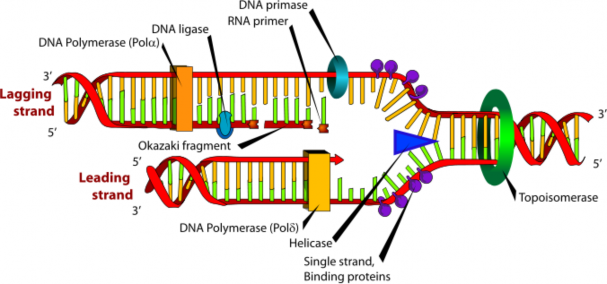
Many replication forks develop along a chromosome. This process continues until the replica- tion forks meet, and the all of the DNA in a chromosome has been copied. Each new strand that has formed is complementary to the strand used as the template. Each resulting DNA molecule is identical to the original DNA molecule. During prophase of mitosis or prophase I of meiosis, these molecules of DNA condense into a chromosome made of two identical chromatids. This process ensures that cells that result from cell division have identical sets of genetic material, and that the DNA is an exact copy of the parent cell’s DNA.
“DNA makes RNA makes protein.” So what exactly is RNA? Ribonucleic acid, or RNA, is the other important nucleic acid in the three player act. When we say that “DNA makes RNA makes protein,” what do we mean? We mean that the information in DNA is somehow transferred into RNA, and that the information in RNA is then used to make the protein.
To understand this, it helps to first understand RNA. If you remember from the chapter titled Cell Division and Reproduction, a gene is a segment of DNA that contains the information necessary to encode an RNA molecule or a protein. Keep in mind that even though you have many thousands of genes, not all are used in every cell type. In fact, probably only a few thousand are used in a particular type of cell, with different cell types using different genes. However, while these genes are embedded in the large chromosomes that never leave the nucleus, the RNA is relatively small and is able to carry information out of the nucleus.
RNA Structure
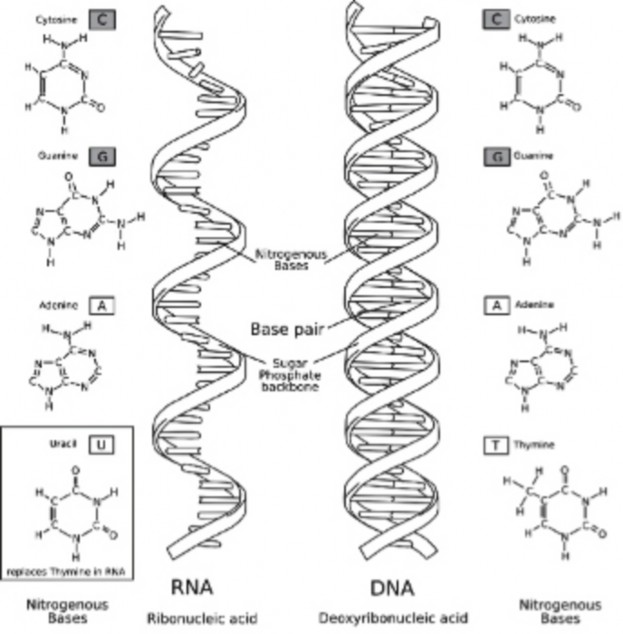
RNA structure differs from DNA in three specific ways. Both are nucleic acids and made out of nucleotides; however, RNA is single stranded while DNA is double stranded. RNA contains the 5-carbon sugar ribose, whereas in DNA, the sugar is deoxyribose. Though both RNA and DNA contain the nitrogenous bases adenine, guanine and cytosine, RNA contains the nitrogenous base uracil instead of thymine. Uracil pairs with adenine in RNA, just as thymine pairs with adenine in DNA. A comparison of RNA and DNA is shown in Table 8.1 and Figure 8.9.
RNA DNA
single stranded double stranded
Specific Base contains uracil contains thymine
Sugar ribose deoxyribose
Size relatively small big (chromosomes)
Location moves to cytoplasm stays in nucleus
Types 3 types: mRNA, tRNA, rRNA
generally 1 type
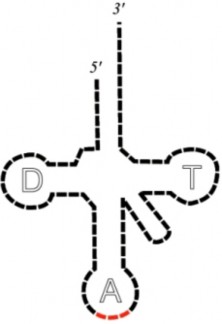
So what does RNA do? There are three types of RNA: messenger RNA (mRNA), transfer RNA (tRNA), and ribisomal RNA (rRNA). All three of these nucleic acids work together to produce a protein. The mRNA takes the instructions from the nucleus to the cytoplasm, where the ribosomes are located. Ribosomes are where the proteins are made. The ri- bosomes themselves are made out of rRNA and other proteins. The mRNA binds to the ribosome, bringing the instructions to order the amino acids to the site of protein synthesis. Finally, the tRNA brings the correct amino acid to the site of protein synthesis (Figure
and Figure 8.11). In mRNA, the four nucleotides (A, C, G, and U) are arranged into codons of three bases each. Each codon encodes for a specific amino acid, except for the stop codons, which terminate protein synthesis. tRNA, which has a specific “3-leaf clover structure,” contains a three base region called the anticodon, which can base pair to the corresponding three-base codon region on mRNA. More will be discussed on these processes during the lesson on translation that follows.
Remember, proteins are made out of amino acids, so how does the information get converted from the language of nucleotides to the language of amino acids? The process is called translation.
Small interfering RNA (siRNA), microRNA (miRNA) and small nuclear RNA (snRNA): siRNA and miRNA are revolutionizing molecular biology, developmental biology, and even medicine. The 2006 Nobel prize in Physiology and Medicine was awarded to Dr. Andrew Fire and Dr. Craig Mello for their discovery of siRNA, which is a type of double-stranded RNA that inhibits gene expression at the mRNA level. Specifically, siRNA acts on ho- mologous processed mRNA by targeting it for degradation. siRNA is responsible for RNA interference (RNAi). RNAi has a natural role in that it is used by plants in defense against plant viral RNAs. miRNAs are also involved in the regulation of gene expression. They are transcribed but not translated into proteins. snRNAs are found within the nucleus of eukaryotic cells. They are involved in a variety of important processes such as RNA splic- ing (removal of introns), and regulation of transcription factors (discussed in Lesson 8.2: Protein Synthesis).
Lesson Summary
Griffith demonstrated the process of transformation, which is the change in genotype and phenotype due to the assimilation of the external DNA by a cell.
Avery and colleagues demonstrated that DNA was the transforming material.
The Hershey and Chase experiments conclusively demonstrated that DNA is the ge- netic material.
Watson and Crick demonstrated the double helix model of DNA.
The Base paring rules state that A always pairs with T and G always pairs with C.
DNA replication is the process by which a cell’s entire DNA is copied, or replicated.
During DNA replication, the two new strands of DNA are “built” in opposite directions, starting at replication forks.
RNA is a single-stranded nucleic acid.
RNA contains the nitrogenous base uracil.
There are three types of RNA: mRNA, tRNA, and rRNA.
mRNA is the intermediary between the nucleus, where the DNA lives, and the cyto- plasm, where proteins are made.
Review Questions
Further Reading / Supplemental Links
Discuss how DNA was identified as the genetic material.
Define transformation.
In DNA, why does the amount of adenine approximately equal the amount of thymine?
What are the base pairing rules?
Explain Watson and Crick’s double helix model of DNA.
How is DNA replicated?
Discuss the importance of mRNA.
Explain the main differences between mRNA, rRNA,and tRNA.
Campbell, N.A. and Reece, J.B. Biology, Seventh Edition, Benjamin Cummings, San Francisco, CA, 2005.
Biggs, A., Hagins, W.C., Kapicka, C., Lundgren, L., Rillero, P., Tallman, K.G., and Zike, D., Biology: The Dynamics of Life, California Edition, Glencoe Science, Colum- bus, OH, 2005.
Nowicki S., Biology, McDougal Littell, Evanston, IL, 2008. The Dolan DNA Learning Center.
http://www.dnalc.org/home_alternate.html
DNA Interactive:
A Science Odyssey:
http://www.pbs.org/wgbh/aso/tryit/dna/
National Human Genome Research Institute:
The RNA Modification Database:
http://library.med.utah.edu/RNAmods/
The RNA World:
http://nobelprize.org/nobel_prizes/chemistry/articles/altman/index.html
Vocabulary
amino acid The monomers that combine to form a polypeptide (protein).
anticodon A 3 base sequence on the tRNA that base pairs with the codon on the mRNA.
anti-parallel Describes the orientation of the two DNA strands; one of the DNA strands is built in the 5’ → 3’ direction, while the complementary strand is built in the 3’ → 5’ direction.
bacteriophage A virus that infects bacteria.
codon A sequence of three nucleotides within mRNA; encodes for a specific amino acid or termination (stop) sequence.
deoxyribonuclease An enzyme which degrades DNA.
DNA Deoxyribonucleic acid, the genetic (heredity) material.
DNA polymerase The enzyme that builds a new DNA strand during DNA replication.
DNA helicase The enzyme that breaks the hydrogen bonds holding the two DNA strands together during DNA replication.
DNA ligase An enzyme that joins broken nucleotides together by catalyzing the formation of a bond between the phosphate group and deoxyribose sugar of adjacent nucleotides in the DNA backbone.
DNA replication The process in which a cell’s entire DNA is copied.
double helix The shape of DNA, resembling a spiral staircase.
gene A segment of DNA that contains the information necessary to encode an RNA molecule or a protein.
lagging strand The DNA strand at the opposite side of the replication fork from the leading strand.
leading strand The DNA strand that DNA polymerase constructs in the 5’ → 3’ direction.
mRNA Messenger RNA; serves as a nucleic acid intermediate between the nucleus and the ribosomes.
nucleotide Monomer of nucleic acids, composed of a nitrogen-containing base, a five- carbon sugar, and a phosphate group.
Okazaki fragments Short fragments of DNA that comprise the lagging strand.
primase An enzyme that builds a short RNA primer on the lagging strand during DNA replication.
purines Nitrogenous bases consisting of two ring structures; adenine and guanine. pyrimidines Nitrogenous bases consisting of one ring structure; thymine and cytosine. ribosome Non-membrane bound organelle; site of protein synthesis.
RNA Ribonucleic acid; single-stranded nucleic acid.
rRNA Ribosomal RNA; together with proteins, forms ribosomes.
sugar-phosphate backbone The sides of the DNA double helix; composed of alternating phosphate groups and deoxyribose sugars.
transcription The process of making an mRNA from the information in the DNA se- quence.
translation The process of making a protein from the information in a mRNA sequence.
transformation The change in genotype and phenotype due to the assimilation of external DNA (heredity material) by a cell.
tRNA Transfer RNA; brings amino acids to the ribosome.
Points to Consider
”DNA → RNA” Can you think of a method in which the information in DNA is transferred to an RNA molecule?
Can you hypothesize on how the As, Cs, Gs and Us of RNA can code for the 20 amino acids of proteins?
Can you develop a model in which the three types of RNAs interact to make a protein?
- Log in or register to post comments
- Email this page